There is simply no such thing as a perfect measurement or a perfect detector. All detectors/measurements have random noise associated with them.
The effect of random noise is that no two measurements are ever exactly
the same. Now, if the noise is sufficiently small, the average person
will not notice this effect in his or her every day life. Without such notice,
the individual labors under the illusion that measurements/science are
perfect To begin with, we will apply the concepts of errors to something that you care about – your exam scores!
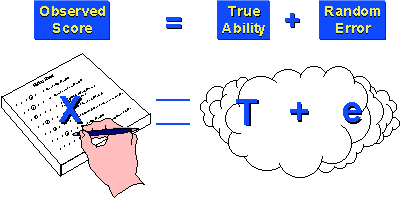
On any exam, your score reflects two things:
These errors works like the following:
 What we measure is X, but what we are interested in is the distribution of the true variable, T. To measure T, however, we have to know what the random error, er and systematic error es is. Without knowledge of er and es, T can never be accurately measured. This potentially is a huge problem. What is er
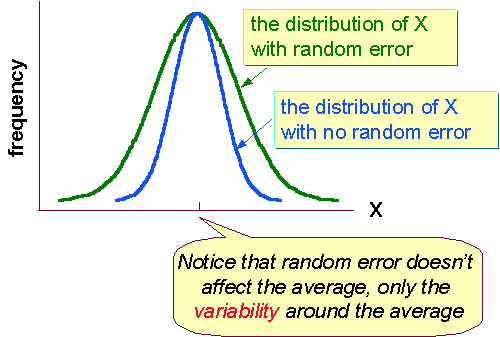 Random errors increase the variability around the mean. (In fact, this process in nature is what drives genetic evolution.) Random errors are associated with apparatus or method used in obtaining the data. All data sampling is subject to random error, period. There is no way to avoid it. You will definitely be dealing with random error and noise in this class. Note that in most detectors, random error is a fixed quantity so that the accuracy of the measurement depends upon the amplitude of the measured phenomena. This idea will become more apparent to you later in the term when we simulate the detection of extra solar planets, among other things. For now, here is a simple example. Suppose I have a thermometer with a fixed random error of +/- 2 degrees. That is the accuracy of this device. Well, if its really 100 degrees out side, then this device will measure the temperature to an accuracy of 2% (2 out of 100). However, if its 20 degrees outside, the device will only measure the temperature to an accuracy of 10% (2 out of 20). What is es? (Systematic Error; often called calibration error).
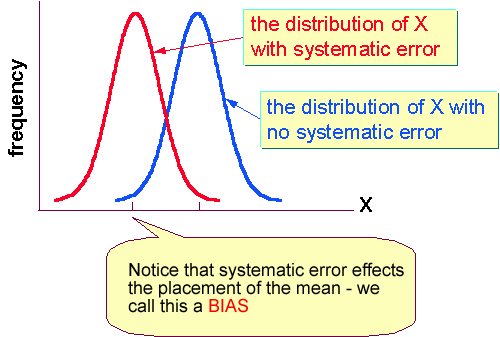 Systematic errors mean that different methods of measurement are being applied to the same variable. This means that the position of the mean is strongly effect. For example, suppose there are two patrolment on the freeway both with identical radar guns. Except that one of them systematically reads 5 mph higher than the other due to a "calibration" error back at the station. Which policeman do you want to speed by? Because of the presence of random error, it is always important to compare distributions via the method we have previously discussed (e.g. the Z-statistic)
For example: Supposed you're in a small class of 25 students. The
average on the first midterm was 75 out of 100 with a dispersion of 15. The
average on the second midterm was 68 out of 100 with a dispersion of 5.
Is there
a significant difference between these 2 distributions?
We find only marginal significance in this case (You should verify this number.) What is different about the two midterms is that the second midterm likely has a lower random error in the way it was graded.
What if N were 100, would the differences be significant? Now, suppose that, for the first midterm, I know that the random error was 12 points and for the second midterm, the random error is 3 points. We will show below that, compensating for this random error, will produce a significant difference between these two exam distributions.
 Here is how you subtract out a known random error. In a bell-shaped distribution, the various components are added or subtracted in quadrature. What does that mean?:
so (true dispersion)2 = (measured dispersion)2 - er2 Example: Suppose a measured distribution has a dispersion of 8 units and we know that the measuring error er is 6 units. What is the true dispersion?
(true dispersion)2 = 64 -36 (true dispersion)2 = 28 (true dispersion) = 5.3 (square root of 28) Now we apply this to the case of our two exams:
Now what do we get using 75 +/- 9 and 68 +/- 4
Significant difference exists; Z-statistic is 3.6
Understanding the role of measurement errors is crucial to proper data interpretation. For instance, the measured dispersion in some distribution represents the convolution of
In general, you only care about the intrinsic dispersion in some distribution. That is, you don't want to have the dispersion dominated by measurement error or poor precision because then you can't draw any valid conclusion. Example: Column 1 contains the data that was measured with good precision. That is, the measuring error of the instrument was less than 0.1. Column 2 represents the same data that was measured with and instrument that had a measuring error of +/- 1 unit:
The first column yields a dispersion of 0.23. The second column yields a dispersion of 1.44. Clearly, the first column is a better measure of the intrinsic distribution of the sample than the second column. Essentially the numbers in the second column are meaningless – because they are dominated by random error due to the imprecise way the quantity was measured.
Note, that your GPA is actually determined in a rather imprecise way.
Your GPA is recorded to an accuracy of 2 digits (e.g. 3.14). Yet
each class is measured far more coarsely (to within a precision
of 0.3 grade points). That way, if you're between an A and a B you would get a 3.5 for your grade (as opposed to either an A- 3.7 or B+ 3.3). Every measurement has an error associated with it and hence a measurement is only as good as its error. Knowing the size of measuring or sampling errors is often difficult, but it still is important to try and determine these errors. For some kind of sampling, error estimation is straightforward. For instance, opinion poll sampling has an error that depends only on the number of people in the sample. This error has to do with counting statistics and is expressed as
For a sample of 16 people, the error would be 4/16 = 25%. This a large error since the range of YES vs. NO is from 0-100% if 12 people answered yes and 4 people answered no then your result would be:
For a sample of 1000 people, the error would be SQRT(1000)/1000 = 33/1000 = 3%. If 750 answered yes and 250 answered no then your result would be:
Conclusion: Always ask what the measuring errors are before anyone claims a significant result!!! /
|
 Nothing could be further from the truth.
Nothing could be further from the truth.